Ever since leaving GetaDoc back in 2015 I had been itching to get myself back into Azure's Platform as a Service (PAAS). My current company didn't have any clients running anything in Azure, nevermind PAAS. 8 months ago I got the opportunity to dive back into the wonderful world of PAAS.
The client was launching their service in the UK and given the regulations around data storage they decided it was best to host an instance of the application in the UK. I was tasked with calculating the cost of hosting the system in the UK on the various cloud providers. He wanted us to focus on the big three: AWS, Google Cloud and Azure
The South African instance of the application was hosted on a Virtual Machine. The client wanted exactly the same thing but in the cloud. I prepared the required presentation and decided I would go out on a limb and try and sell moving the system over to Azure's PAAS. It would work out better for the client and us as neither of the parties had proper system administrators. After giving a very convincing presentation to the client they agreed that this was the way forward.
About two months after we went live in the UK, the client started having issues with their South African hosting. The hosting provider was not able to reliably keep the system up. The client decided to move everything over to Azure's PAAS.
Below I have documented the issues of converting the system to Azure PAAS, along with the migration issues we had with moving a live system to Azure.
The traditional hosting set up.##
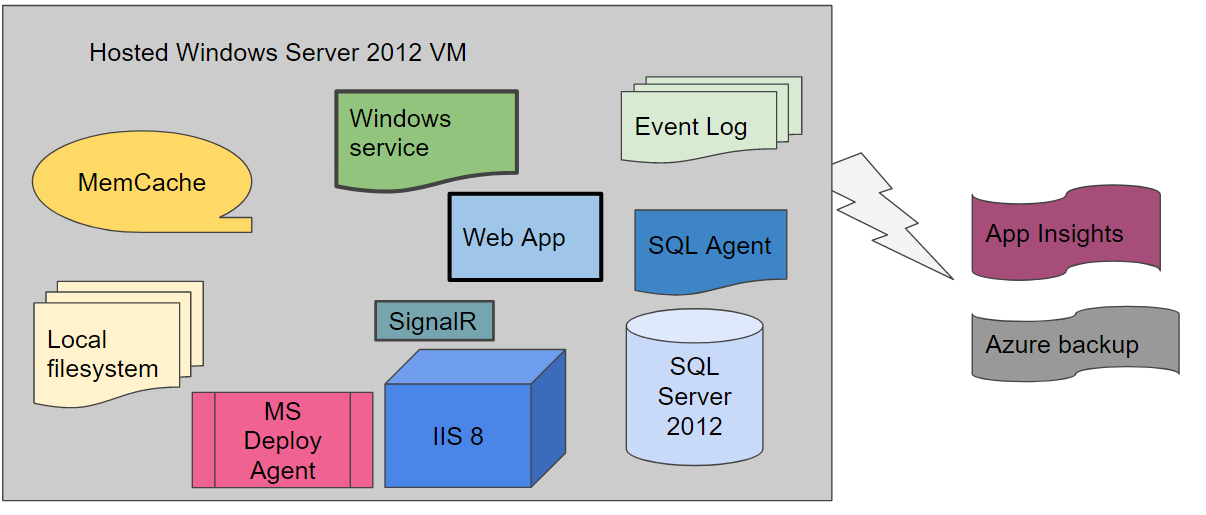
The application, like most enterprise applications, had a lot of moving parts that had to be mapped into Azure. The application at its core is a web application. It stores data in a database and the file system. It has VOIP integration using SignalR to deal with this. It made use of a Windows Service to do any background jobs.
We had already started implementing some Azure functionality in the form of Application Insights and Azure backup. This was my influence upon moving to the company.
The plan was to ensure there were no virtual machines. This meant that there were a few components which would require code changes to ensure we could map them to Azure components. The curve ball was that the application still needed to be able to run on a Virtual Machine. This meant that everything needed to be configurable. It also needed to be setup in a way that allowed a Hybrid option consisting of both Virtual Machines and Azure PAAS components.
The PAAS set up
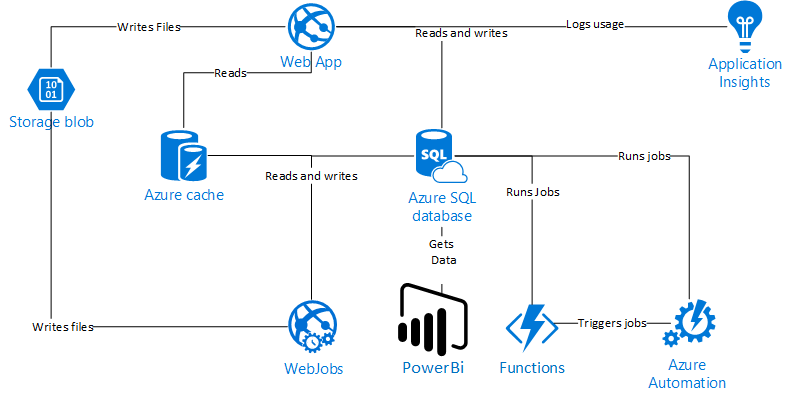
We had successfully mapped every component within our traditional setup to an Azure PAAS component. Looking at the above diagram if you were thinking it was a simple process and couldn't have been painful you would be wrong.
Code changes
The code base was created about 4 years ago. The technical requirements to ensure we could make storage configurable were not a common requirement. This meant we had to refactor a great deal of code to ensure the simple File.Read and File.Write commands were moved to a configurable component that we could switch out to Azure Storage. This affected document storage right through to email attachments.
Luckily caching was designed better and it required less work to ensure it was configurable. We had issues with caching timeouts that weren't as gracefully handled as they should be. This was due to our traditional MemCaching component being on the same machine as everything else and the timeouts were rare. We learnt to implement proper retry patterns on caching and many other components likely to cause the same issues.
We decided to move the documents that were being stored in the database to Azure Storage to ensure our database restores were quicker. This was a fairly easy task but it did surface some "quick fixes" that had turned in to technical debt that we ended up fixing.
Overall we have matured our code base to ensure that every component is highly configurable as well as fixed some long outstanding technical debt.
Database and MemCache to Azure Redis Cache
We made use of a combination of caching within the system before the move to Azure. We primarily made use of a database cache which consisted of a single table and a simple Key value structure. The database structure existed to enable caching within our stored procedures. We had started to implement Memory cache for the very frequently used things.
We had a longstanding problem where we would get deadlocks on the caching table due to multiple reads and writes on the same table.
We decided to overhaul the whole system to ensure that it was a two stage caching system and of course highly configurable.The two stage system was to work as follows:
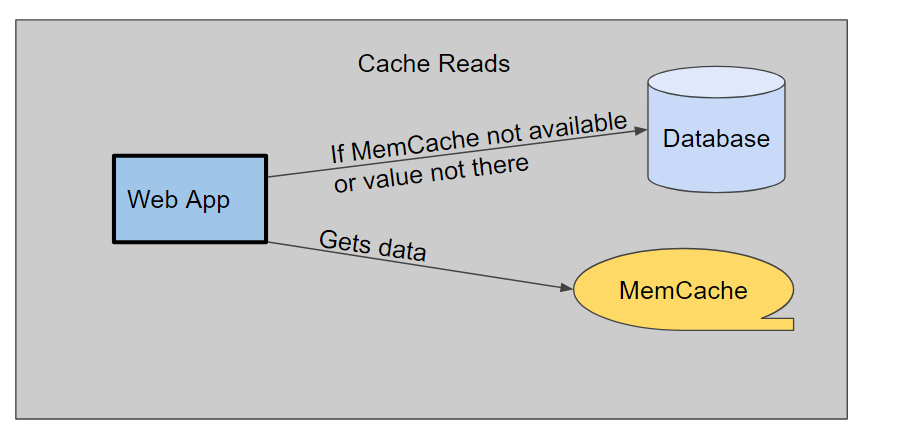
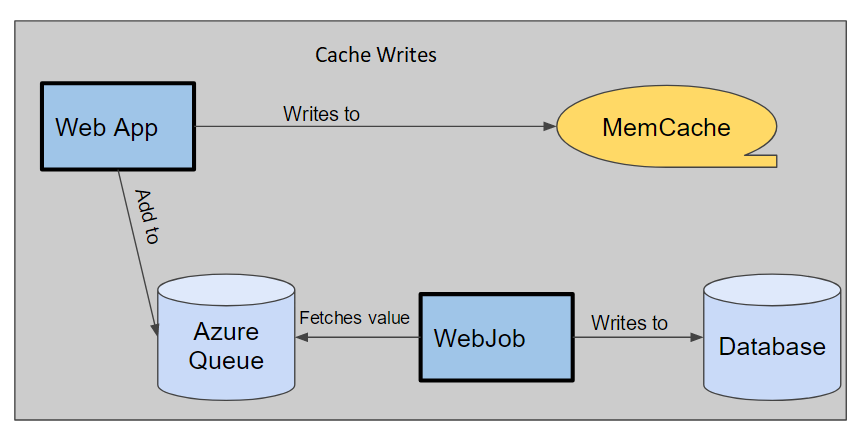
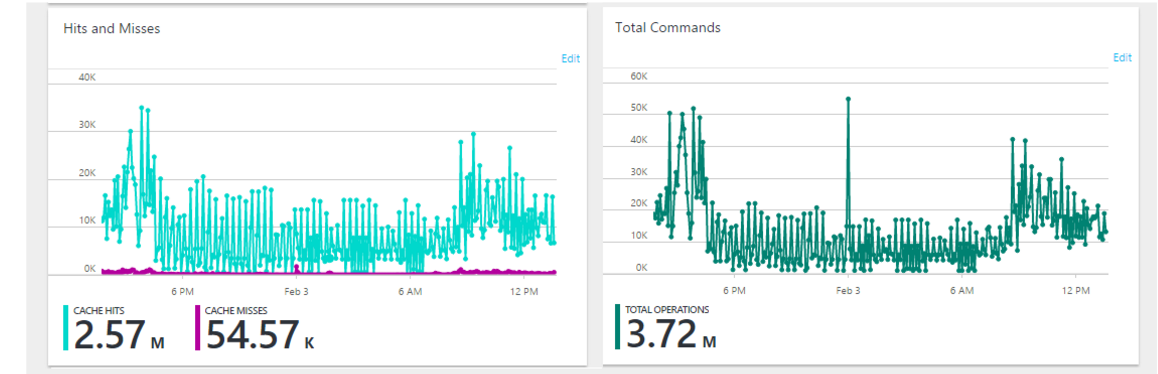
This meant we had multiple safe guards in place in the event of a failure in any caching component. However within 6 hours of going live on Azure we found that 50 % of the database activity was spent writing to that table. Luckily with it all being very configurable it was just a matter of turning off the database caching off and the system performance returned to normal. In hindsight this overhaul saved the launch from being a complete disaster. We since removed the database cache as upon doing research realised it was a very bad design decision.
We had chosen a basic price tier.. Azure had rated the tier perfect for development and testing however we thought it sufficient for our application. It worked wonderfully but it had a very bad habit of clearing all the values every 14 days. It was a documented, read StackOverflow, feature that could not be fixed. It is a not production-ready pricing tier and often the underlying machine needs to restart. We upgraded to a standard caching tier and the problem has since gone away.
The most amazing thing that we got straight out of the box was metrics. We didn't have a clue on how much our cache was being hit and it was fantastic being able to answer all of those "I wonder" questions previously.
Logging
We use Log4Net extensively in the application and were writing log files on the traditional virtual machine's file system. Writing to the file system within Azure App Services is not feasible as there will be more than one instance of your app running in the cloud. This meant we had to find another way to do logging.
Our first attempt was to write the logs to Azure Table Storage. This worked wonderfully for a few months however it then got slower and slower to query the log files. This was due to the indexing not being very good on anything but the Primary and Partition key. We have since moved it to its own SQL Azure Database. This is much better and it provides us with a very effective way to search our logs and was a big upgrade from text files.
IIS to App Services
This was probably the component the offered up the least resistance. It was very much a case of lift and shift and then change the settings for the other components. The only problem was trying to work out what the ideal number of instances should be.
The Autoscale feature has proved to be nothing short of unbelievable in solving this problem. The Autoscale feature allows you to set up rules for when and how it is meant to scale out or in.
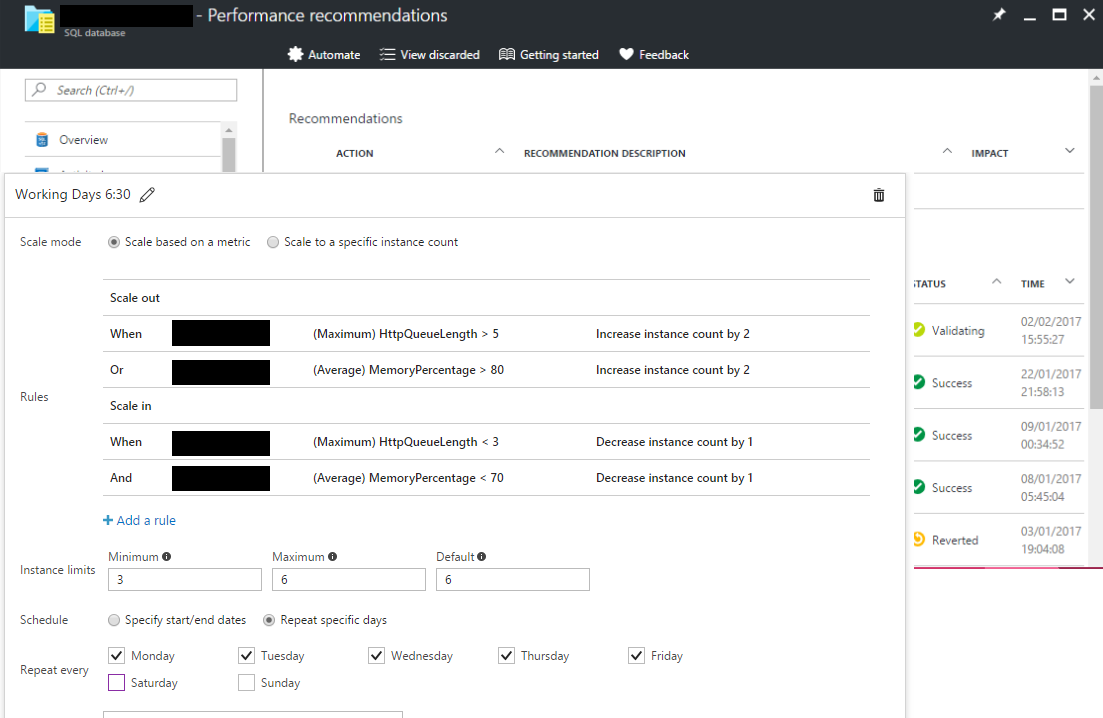
The only issue we ran into was that SignalR had been set up to run using "In memory" session storage and as a result would not work properly when running on more than one instance. We configured this to store it in the SQL Database.
Windows Service to WebJobs
WebJobs
WebJobs are background jobs that run on top of an App Service. They can be configured to run on a trigger or to run continuously. The latter was a perfect fit for our Windows Service. We had managed to write the Windows Service quite well and was a matter of creating a WebJob project and adding a reference to the Windows Service DLL. In short it could not have been easier.
We found that when the WebJob was doing CPU intensive workloads the application would become very slow to respond. This is because WebJobs share the same instance as the App Service it is loaded in to. This results in the possibility, as we experienced, of the WebJob impacting your application. We decided to move it out to its own App Service Plan.
SQL Server to SQL Azure
SQL Azure has finally caught up to the fullblown SQL Server Instance you can install on a machine. It is, at its core, database-as-a-service. However, it was the problematic component with regards to the migration. Let me explain
We had a whole lot of periodic jobs that ran in the SQL Server agent on the virtual machine. SQL Azure has not got a SQL Server Agent and as a result we had to source other ways and means of triggering these. We managed to leverage Azure Functions, more on that later.
The performance tiers are very confusing. It makes use of a performance unit called a DTU. The metric is a combination of IO, CPU and Log IO performance. This sounds simple enough but there are no reference points to work off until you try and apply a workload to it. To make life even more confusing there are three performance tiers Basic, Standard and Premium.
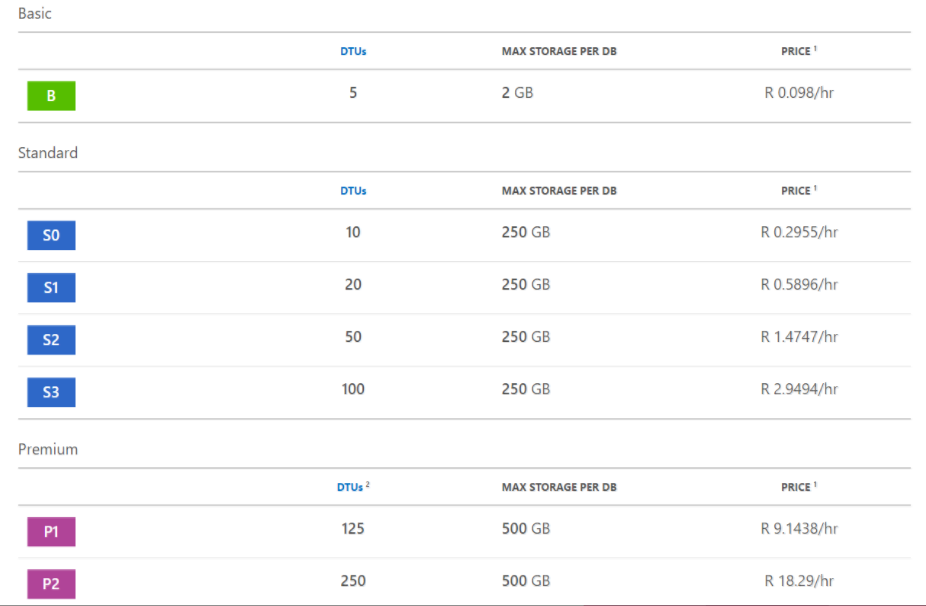
The jump from an S3 to P1 is only 25 extra DTUs so assume it’s only a 25% increase in performance for 3 times the price. The difference between a S3 and P1 should be seen as 200% as, we have been told from Microsoft, the IO is significantly faster in the Premium tier. This has led us to ignore the DTUs entirely and just focus on deriving performance from the % change in price.
We hoped to get away with an S3, however, with the client growing at such a rate, and some bad technical debt around SQL optimisations, we had to move to a P1. Subsequently we have had to move to P2 due to the clients increased growth.
We had hoped to set up a secondary read only in another region for Power BI to query against. This is a very nifty feature where with a few clicks it is possible to spin up a read-only replicated secondary in another datacentre. Unfortunately, it is not possible to set it up across performance tiers. So, if you have a Premium tier database you cannot have a standard read-only copy running in the other datacentre. We had to come up with another plan for Power BI which you can read about here.
The client is office hours focused and at night the system is not being used so we had hoped to scale the database up and then down during the day depending on usage. However, there is no Autoscale feature like we got out the box from App Service Plan. We had to write an Azure Automation job to handle the scaling on a schedule. We discovered that when scaling the database there is downtime and this meant we could not scale during the day. We had to take the peak usage and scale to that level before office hours and scale it down after office hours. This was frustrating as it was costing the client a fair amount extra for a feature that should just be available out the box.
Scaling between tiers also seemed to take a long time. Scaling from a Premium tier to a Standard tier could take anywhere from 10 minutes to 2 hours. We managed to pose this question to Microsoft SA and the answer as follows. Azure has to move the database to a completely different underlying hardware. This takes time and as a result does result in it taking some time and minimal downtime.
I may have painted a really awful picture of SQL Azure above but the benefits of it are by far worth the negatives. First and foremost, you are always on the cutting edge and you never had to pay for a new licence. SQL Azure gets all the new features before the on-premise versions do.
We get point-in-time restore right out the box. This means you can restore the database to any point in time in the last 30 days. This has proved to be very powerful for us and has resulted in big debugging finds. It also means we do not have to worry about a backup strategy and more importantly testing the restores actually work. The saving in the client’s as well as our time has paid for itself many times over.
SQL Azure has Automatic tuning. It runs machine learning against the database and calculates which indexes are missing and which indexes should not be there. It then applies the change and monitors the change over the next 24- 48 hours, if performance improves it leaves it and if it makes it worse it reverts the change. This has saved us countless hours of time performance tuning the database. It is like having an automated DBA.
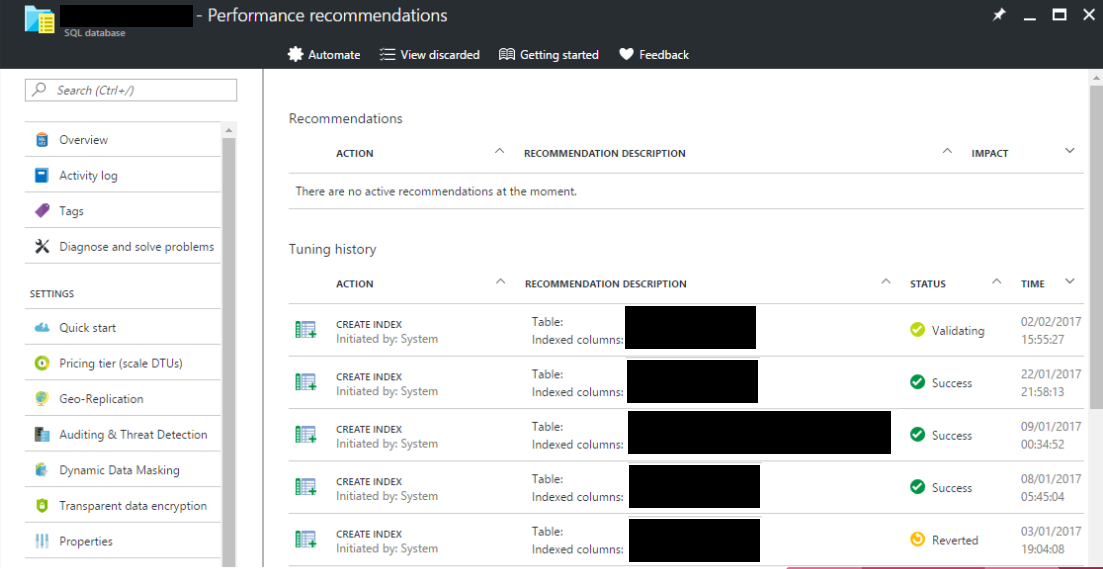
SQL Azure has built in threat detection that helps give us piece of mind that the data is secure and being monitored by the best. We also get encryption at REST which is a requirement for a few regulatory bodies that we have to conform to.
The real win of SQL Azure for us has been the metrics we get out the box. Query performance insights is basically a very user friendly view of a SQL Server 2016 feature called query store.
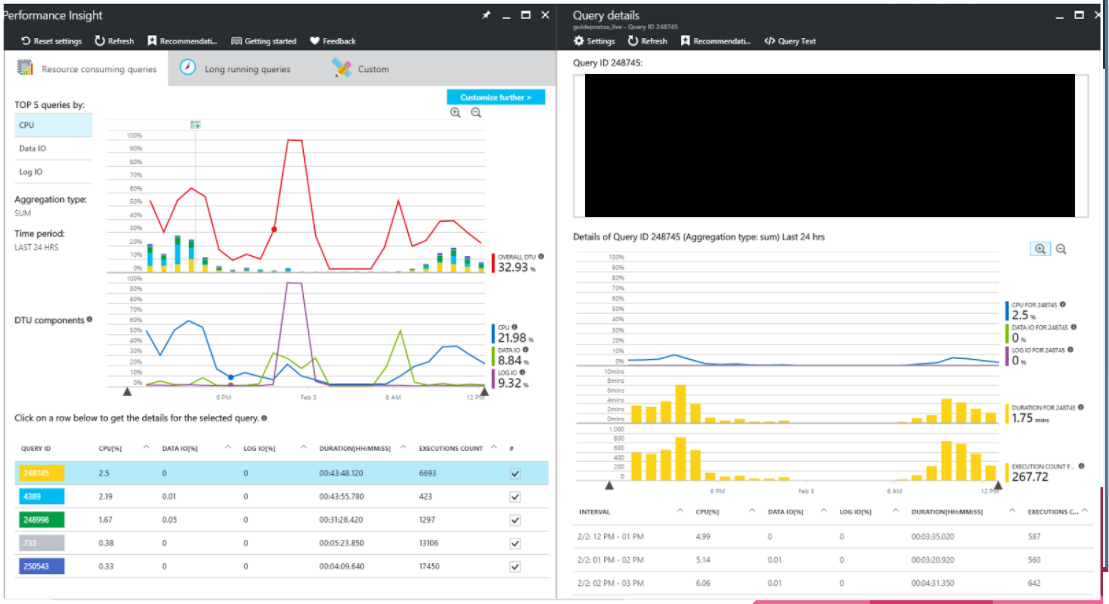
It helped us within 6 hours of going live discover the caching bottleneck. It has helped us improve queries that we previously didn’t know were big resource consuming queries.
SQL Azure has made our lives so much easier and there is no going back to normal databases. It takes fair amount of effort but once you are finished going through the initial setup issues it starts reaping the benefits, especially if you don’t have a Database Administrator.
Azure Functions and Azure Automation
Azure functions and Azure Automation were not part of the initial plan but ended up being crucial to the running of the system. They provided an effortless way to script the things that were missing from the various components. We used them in a mainly DevOps manner.
Azure functions allows you to write C# code that can be triggered on a variety of things. We especially like the time trigger, it uses a CRON expression to kick off the function on the schedule. We use it for re-indexing of the database and other simple database jobs that would have been previously be triggered by the SQL Server Agent. We are looking at extending our use of the Azure functions to actual system functions that go beyond DevOps.
Azure Automation allows us to write PowerShell scripts to automate things like database restores and scaling the databases. The UI for it has not been thought out too well and their scheduling component has left us bewildered from a user experience point of view. However, it is very powerful and it is key to driving the Adhoc jobs the client may want to do.
Conclusion
The migration has been a tremendous success, even if we did go over budget. The proof of the success was that the client was offered the migration back and turned it down.
It has allowed us to expand the client’s system effortlessly and it has enabled our tech savvy client to start using other features of Azure to integrate with ours without intervention from our side. We are very happy to be on a platform that allows us to not be limited by infrastructure and allow us to do what we need to do when we need to do it.
On a more personal note, this migration has been the highlight of my career. It is in the top 3 of my personal achievements. I can not rave about the platform enough and believe it is the future.